In 2015 I built a system to safely execute untrusted Java code submitted by students in Moodle. The core idea was straightforward: give every student a dedicated virtual machine, route their code execution through it, and isolate any damage to that single disposable environment.
It worked. But VMs were heavy. Each Oracle VirtualBox VM took seconds to start, consumed gigabytes of disk, and required a full OS per student. At university scale that was acceptable. At production scale it would not be.
This post rebuilds that architecture using the tools available in 2026. The threat model is identical. The implementation is dramatically lighter.
The Original Architecture
The 2015 system had four layers:
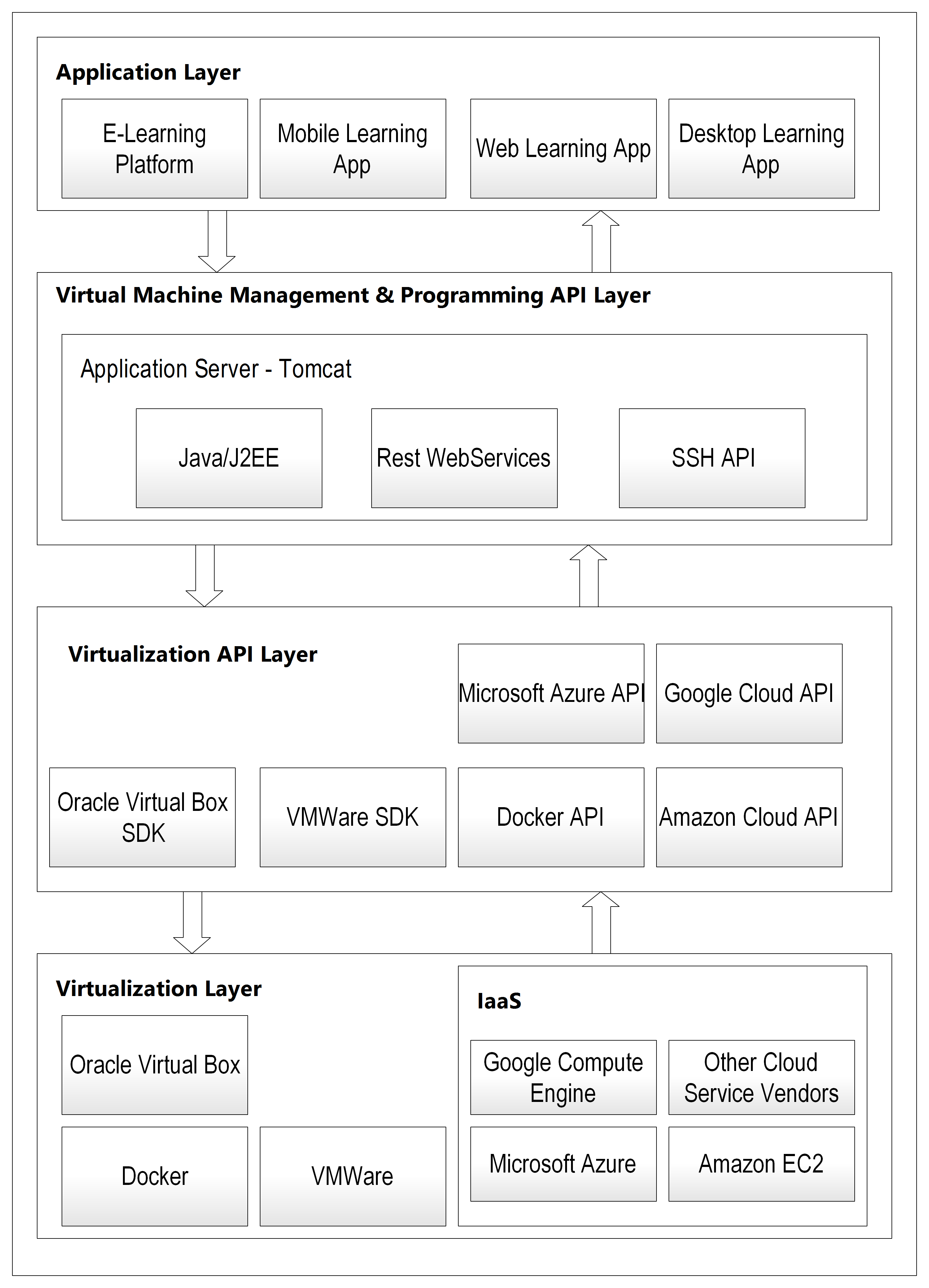 Original four-layer thesis architecture — SliTaz Linux VMs at the base, VBox SDK above it, Java/Tomcat REST API in the middle, and Moodle plugin at the top
Original four-layer thesis architecture — SliTaz Linux VMs at the base, VBox SDK above it, Java/Tomcat REST API in the middle, and Moodle plugin at the top
The REST API in Layer 3 exposed these operations:
POST /vm/clone → clone base VM, assign to student
POST /vm/{id}/start → boot the VM
POST /vm/{id}/execute → SSH in, compile and run code, return output
POST /vm/{id}/stop → shut down
DELETE /vm/{id} → delete clone
Every student got their own VM cloned from a minimal SliTaz Linux base image — 30MB, just enough for SSH and a JRE. If a student's code crashed the VM, it was deleted and cloned fresh. The host was never touched.
The architecture was already correct in 2015. The thesis even noted Docker as the natural next step in the future work section. At the time Docker was too new to rely on in an academic context. That constraint no longer exists.
What Changes With Docker
The core security guarantee stays the same — isolated execution environment per submission, disposable after use. What changes is how that environment is implemented.
VMs → Containers
A Docker container starts in milliseconds, not seconds. It shares the host kernel rather than running a full guest OS, which means the overhead per execution drops from gigabytes to megabytes.
FROM eclipse-temurin:21-jre-alpine
RUN adduser -D -s /bin/sh runner
WORKDIR /code
USER runner
CMD ["sh", "-c", "javac Main.java && java -cp . Main"]
This base image is ~180MB — heavier than SliTaz but still trivial compared to a full VM. More importantly it starts in under a second.
VirtualBox SDK → Docker API
The VirtualBox SDK (vboxjws.jar) in Layer 2 mapped to the Docker Engine API. Both expose programmatic control over container/VM lifecycle.
// 2015: Oracle VirtualBox SDK
IVirtualBox vbox = manager.getVBox();
IMachine machine = vbox.findMachine("student-42");
machine.launchVMProcess(session, "headless", null);
// 2026: Docker Java SDK
DockerClient docker = DockerClientBuilder.getInstance().build();
CreateContainerResponse container = docker.createContainerCmd("grader:latest")
.withName("student-42")
.withMemory(256 * 1024 * 1024L)
.withCpuPeriod(100000L)
.withCpuQuota(50000L)
.withNetworkDisabled(true)
.exec();
docker.startContainerCmd(container.getId()).exec();
Notice what's embedded directly in container creation: memory limits, CPU quota, and network disabled. In 2015 these required separate configuration steps. In Docker they are first-class API parameters.
SSH code transfer → volume mounts
The 2015 system used SSH to copy source files into the VM before execution. With containers, a volume mount or a simple file copy via the Docker API is sufficient.
// Copy source file into running container
docker.copyArchiveToContainerCmd(containerId)
.withHostResource("/tmp/submission.tar")
.withRemotePath("/code")
.exec();
Resource limits
The 2015 architecture had no built-in resource limits on the VMs — they were addressed in future work. Docker cgroups solve this directly:
HostConfig hostConfig = HostConfig.newHostConfig()
.withMemory(256 * 1024 * 1024L) // 256MB RAM hard limit
.withCpuPeriod(100000L)
.withCpuQuota(50000L) // 50% of one CPU
.withPidsLimit(64L) // no fork bombs
.withNetworkMode("none") // no network access
.withReadonlyRootfs(true) // read-only filesystem
.withTmpFs(Map.of("/code", "rw,size=10m")); // small writable temp
This single configuration block closes most of the threat model from the original thesis:
- Memory exhaustion → hard limit via cgroups
- Fork bombs → pids limit
- Network access → network disabled
- File system damage → read-only root, small writable tmp
Execution model: per-submission, not per-student
The 2015 system allocated one VM per student for the duration of a quiz. This was necessary because VM startup time was too slow for per-submission allocation.
With containers starting in milliseconds, you can allocate one container per submission instead — start it, run the code, capture output, destroy it. No state persists between submissions.
public ExecutionResult execute(String sourceCode) {
String containerId = createContainer();
try {
copySource(containerId, sourceCode);
startContainer(containerId);
return waitForResult(containerId, timeout: 10s);
} finally {
removeContainer(containerId); // always destroyed
}
}
Adding Kubernetes
For anything beyond a single server, Kubernetes adds orchestration without changing the security model.
apiVersion: batch/v1
kind: Job
metadata:
name: submission-42
spec:
template:
spec:
restartPolicy: Never
containers:
- name: grader
image: grader:latest
resources:
limits:
memory: "256Mi"
cpu: "500m"
securityContext:
runAsNonRoot: true
readOnlyRootFilesystem: true
allowPrivilegeEscalation: false
Each submission becomes a Kubernetes Job. The cluster schedules it, runs it, collects output, and cleans up. The REST API in Layer 3 becomes a job submission API — the same contract as before, with Kubernetes handling execution instead of direct Docker calls.
The Architecture Today
Layer 4: Application Layer (Moodle plugin, web app, or API client)
↓ REST API calls (same contract as 2015)
Layer 3: Submission API (Spring Boot)
↓ Docker API / Kubernetes Jobs API
Layer 2: Container Runtime API (Docker Engine / containerd)
↓ controls
Layer 1: Container Layer (Docker + cgroups, or Kubernetes pods)
The four-layer separation is preserved. Layer 3 is still a REST API accepting source code and returning results. Layers 1 and 2 have been swapped for container primitives. Layer 4 is unchanged — it still just makes HTTP calls and doesn't know what runs beneath.
For Higher Security Requirements
If the threat model requires kernel-level isolation without full VM overhead, two options are worth considering:
gVisor intercepts system calls in user space, providing a sandboxed kernel interface without running a full guest OS. Drop-in replacement for the Docker runtime.
Firecracker is a microVM hypervisor used by AWS Lambda. Sub-second startup, hardware-enforced isolation, minimal memory footprint. The strongest isolation short of a full VM.
Both integrate with the same container tooling — the Layer 3 API doesn't change.
Final Takeaway
The 2015 thesis got the architecture right. Four clean layers, each independently replaceable, with a REST API contract between the application and the execution infrastructure.
What has changed is the implementation of Layers 1 and 2. VMs have been replaced by containers that are faster, lighter, and better equipped with resource controls. The security model is the same. The operational overhead is dramatically lower.
If I were building this today, the Spring Boot submission API would look almost identical to the 2015 Java/Tomcat REST service. The VirtualBox SDK calls would be replaced by Docker API calls. Everything else — the layer separation, the per-execution isolation, the disposable environment model — maps directly.